
Unlocking Databricks’ full potential requires a new approach to data management.
Discover how “The Three Ways” — the core principles of DevOps — form the foundation of modern DataOps, and will revolutionize your data engineering practice.
Imagine you’re the leader of a data team and you’re sure that the time has come—enough is enough— you need a fresh data platform.
Yet you can’t quite take the leap. While it promises to solve problems and deliver substantial value, the prospect of adoption feels rather daunting. The benefits don’t appear to outweigh the pain of the disruption to your team and to your operations.
True, if you bought into every vendor’s pitch, you’d spend all your time moving platforms and never delivering.
However, some technologies stand out from others, and some become essential over time. This is the lifecycle of technology adoption. There is always some friction when it comes to doing something new. It feels hard, and perhaps it is hard to “cross the chasm”, both on a personal and a professional level, but change is what is necessary for growth.
It’s why the leaders in every field are often there because they dared to be disruptive. They embrace and create change. Healthy disruption is at the heart of Databricks. For over a decade, Databricks has been stacking S-curves on top of each other and releasing them freely to help solve the world’s data problems. Spark, Delta Lake, and MLflow, (and increasingly even Unity Catalog) are ubiquitous throughout most data stacks. It’s why over 10,000 customers to date have chosen to go with Databricks.
How then, can you take the leap with Databricks?
You need to change the bond between technology, people, and process. In other words, you need a DevOps transformation, but for data. You need DataOps.
There are many articles out there claiming that DataOps is not ‘DevOps for Data’. But I beg to differ, to know DataOps means to know DevOps deeply, and herein lies most of the problem.
What is DevOps?
My favourite definition of DevOps comes from The Phoenix Project, which states that DevOps is the act of taking the best practices from physical manufacturing and leadership and applying them to the technology systems we build to achieve our means.
The principles the above quote alludes to come from some of the below movements:
- Lean Manufacturing
- The Theory of Constraints
- The Toyota Kata
- The Scientific Method
- The Agile Manifesto
- (Lean) Six Sigma
DevOps is, at some level, about what we all typically think it is: automating the tasks of IT operations, writing “Infrastructure as Code,” and bringing the “Dev teams” closer to the “Ops teams.”
But these things are the consequences of applying the teachings of these movements to deliver a more robust, reliable, and productive software product.
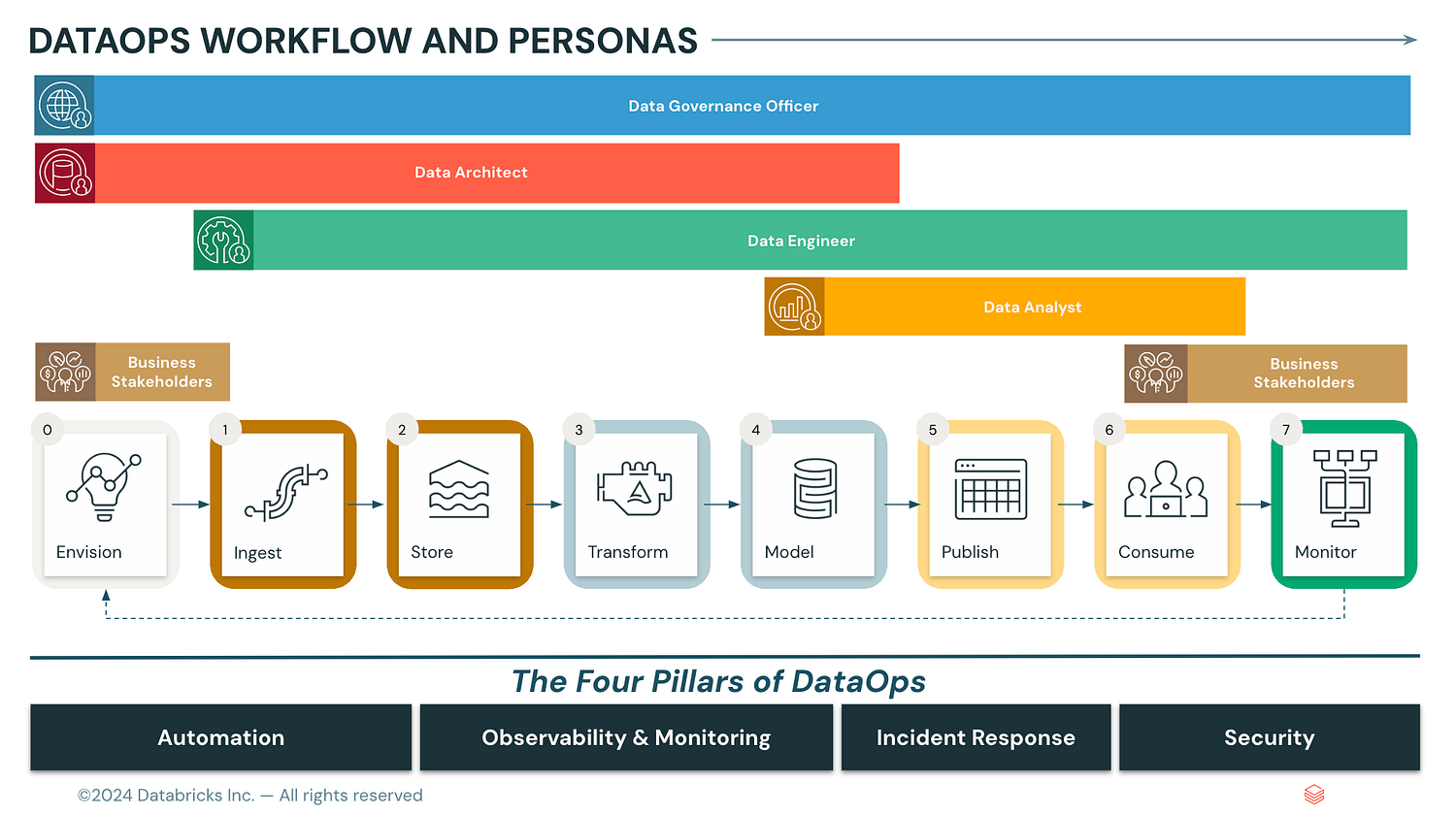
The trick to DataOps, then, is to think about how these principles and this culture can be applied to “data products” as they relate to the IT systems we build to deliver them. It’s about working from first principles and leveraging the lessons of the past. In Gene’s Kim definition, we can embody this through “The Three Ways of DevOps”.
So, let’s go through each of The Three Ways and apply them to Databricks to get — The Three Ways of DataOps for Databricks.
The First Way of DataOps and Databricks
Make analytics flow from left to right, from Dev to Ops, as quickly as possible.
The key to thinking around the first way is to think of all work in data analogous to a physical factory pipeline; data goes in as the raw material, and valuable insights come out. Just like a manufacturing plant producing refined oil, we make data products, and we must aim to optimise the throughput of these products without sacrificing their quality.
I’ve found this to be a brilliant metaphor to guide our overall approach to data work. Think of developers as literally the engineers on the factory floor who construct and orchestrate the machinery needed to create analytics.
Consider how their work gets done. When a requirement comes in, what actually happens from start to finish? How many people are involved? How many teams, and how many different technologies? How do they test if the requirement was met? After it’s deployed, who ensures it continues to run? What Service Level Objectives are essential to this workload?
Through this process, I guarantee you’ll find that every handoff between individuals, platforms, and especially teams incurs a considerable loss in time and productivity. This is why DevOps exists: to merge the roles and responsibilities of Developers and Operations into one, to prevent information loss, to make technology reproducible (think IaC, VMs, and Docker), and to relieve the constraints that cost us time.
This is where Databricks steps in. There are many reasons to buy Databricks, but in my opinion, you are primarily purchasing Databricks for the ability to streamline your processes and maximize analytical throughput. Business use cases are a dime a dozen, but the machinery to produce them doesn’t just magically appear. For example, there are lots of painful problems to solve before you do anything actually useful with data, such as:

Databricks has an answer for all these challenges. You might think the answers to these questions are trivial, but to build them yourself in a fragmented data landscape is not at all. It’s work that weighs on you. To put it in SRE terms, Databricks is a means to eliminate toil. In practice, we typically see this translates to an average doubling in developer productivity. That’s twice as much work flowing from Dev to Ops!
This is why Databricks is a “data hyperscaler.” It is a uniquely vertically and horizontally integrated data stack; everything is in one place, reducing the need for handoffs and data movement. It relies on universal cloud services and open data formats and integrates with almost every data tool on the market.
With that in mind, if you examine how your analytics factory works today, I can almost guarantee that the flow of work from Dev to Ops will be bottlenecked at a point where technology and people intersect. This is the real value of Databricks: it brings your team together on one platform, increasing analytical throughput by reducing handoffs while using open data formats to allow for heterogeneity of ways to interact with your data.
The Second Way DataOps and Databricks
Make your Lakehouse a safer and more resilient system by receiving feedback as soon as possible.
In the second way of DataOps, your goal is to enable your engineers to make changes to your analytical pipelines without fear. Imagine a new intern joining the team. Could they push a simple change to production, like renaming a column in a table in less than one day? Does the prospect of that change send a shiver down your spine?
The only way to do this safely is to create consistent, fast, and reliable feedback loops. It is the key to building resilient and adaptable data products.
Fortunately or unfortunately, there is typically only one way to get that feedback, and it’s a word many data engineers fear… testing and lots of it.
When a faulty car is produced at the factory, it’s real and tangible, we can see it (hopefully). But in software systems, it’s invisible unless you specifically test for it, which doesn’t mean the consequences can’t be as dire. Like the great Edsger Dijkstra said — “Testing can be used to show the presence of bugs, but never to show their absence”.
This is critical today as data analytics isn’t simply about Tableau dashboards anymore. Data products are almost always operational in nature. A simple forecasting engine breaches SLAs for one day, and millions of dollars can be lost. A bad input goes into a risk lending model, and someone’s insurance can be rejected.
In reality, all developers, even data developers, test all the time, just with their eyes. How do they know what they built worked otherwise? Tests of any kind are the formal verification of requirements. The tricky part of testing is the effort required to codify and automate your expectations.
Testing can be simple in practice, data pipelines are straightforward, one-way processes. Imagine a mathematical function: f(x) = x * 2. If I put 2 in, I should get 4 out. A business rule is just the specific application of a function; it’s hardly different. A supermarket might double the reward points it gifts customers when they buy its in-house brand.
The beauty of owning a data lake and adopting the medallion architecture is that storage is decoupled from compute. This means that, in practice, it is simple to deploy two different versions of your pipelines and run them side by side with the same inputs. This is because every data pipeline is essentially a black box function, data goes in, and different data comes out. You have a space to try new things out safely and do things such as make sure those transformations are as expected. This can be done with a basic PyTest suite combined with Chispa and dbldatagen or something more out of the box such as Delta Live Table Expectations.
This is where we start to encounter one of the core problems in data as a whole. Data is a living being. It is constantly morphing and changing. In fact, if we weren’t continually checking for change, there would be little value in data at all.
It’s a painful reality of working with data that when we develop, we have to make assumptions about the nature of the data we are expecting as input. These assumptions can’t constantly shift; if they did, the code would have to change with it and, therefore, the code never gets done. Likewise, in production, the opposite applies: the data changes constantly, but the code itself is static. That way, we get those expected new insights with fresh data inputs, but without regressions in functionality.
This is the duality of data engineering. Our process is always divided into two pipelines: one for creating the code to do new things with static inputs, and the other for realizing the value of that innovation by feeding it fresh data. Reconciliation ofthese two pipelines is a challenge for all data teams, large and small.
Databricks, Unity Catalog and Delta Lake can help you solve this dilemma. Many tradeoffs need to be considered to solve this problem in full, which will be discussed in another post, but given storage is cheap, and compute is decoupled in a Lakehouse, a simple solution could be to take an entire database and Delta Clone it. This would give an isolated representation of production in a lower environment for all your developers to work with but at the cost of working with production volumes and compute (with potential security implications). You can do this with either deep or shallow clones too.
Once you have cloned your production data, the next step is to analyse and understand it thoroughly. You need to profile the inputs using tooling like Lakehouse Monitoring or in-built profiling and align them with expectations. You would repeat this process for every stage of your pipeline to get feedback on the behaviour of your code.
Now if you had absolute certainty of what those inputs are and you automated those checks to a high test coverage, the change from your intern is pretty straightforward. The new pipelines are deployed in isolation and it either passes or it doesn’t. The beauty of Unity Catalog too, is if they don’t pass, you have all the lineage up and downstream of that change, and every query that has followed it too, all tracked, so you can identify and remediate quickly what broke.
Turn the same process on in production and this solves the second part of the equation: knowing our inputs and continuing to check that they are as expected when actual data is flowing through your production pipeline. After all, valuable analytics can only be created in production when new data is fed into it.
The Third Way of DataOps and Databricks
To combat the entropy of data systems, foster a culture of constant experimentation and improvement that is aligned with the Databricks roadmap.
There are two keys to living in the third way. The first is having a scientific mindset, and the second is being able to reserve time to build for the future. They go hand in hand, allowing you to form hypotheses about improving your processes while giving you the breathing space to act on them and see the results.
Ward Cunningham wisely said — ‘Shipping first-time code is like going into debt.’ This rings true for data teams too. Tech debt silently accumulates, and most organizations lack the resources to repay it. Addressing it early is key to maintaining agility and efficiency. I personally have seen time and time again how the burden of keeping the lights on leads to perpetual toil. If you spend 100% of your time putting out fires to keep production alive or attempting to maximise developer throughput, there’s no time to improve your system to prevent the fires from occurring in the first place, or to lift the constraints that are hampering the amount of work that can flow from Dev to Ops. It is a perpetual ball and chain around your ankles.
For example, in the past two years, if you take all the repeating BI queries that have ever run through DBSQL over all Databricks customers, they are running 73% faster on average than they used to be. Given that time is money in the cloud, that is a three-quarter reduction in cost for nothing. If two years ago you planned to adopt DBSQL, you essentially just got this benefit for free and fully realised it.
On the flip side, if you decided to bolt on a complicated YAML metadata-driven framework over Databricks, you might find yourself locked into an old Databricks Runtime, and unable to realise these improvement benefits without a substantial refactor. You need in-depth knowledge of how this abstraction works, or you’ve now essentially locked yourself into an outdated version of Databricks.
Whatever situation you happen to be in, a future target state is always there to be found. Databricks is a rapidly evolving product. Rarely do three months pass without a significant feature being released on the platform. At the time of writing, we are approaching Spark and Delta versions 4.0, and Databricks will be the first platform to integrate the two seamlessly.
You could form a hypothesis that with Delta 4.0, your Spark SQL queries on Delta 3.1, given they parse a lot of unstructured JSON, will speed up by 30% through the use of the new Delta Variant Type. So you action a plan to set aside the time to identify 5–10 representative queries and set up a test environment to compare their performance with and without Delta Variant. If the average improvement is close to 30%, you then plan to upgrade to Delta 4.0 and identify the next obstacle in the way.
The key takeaway here is that staying current with Databricks isn’t just about adopting new features. It’s about embracing a mindset of continuous improvement. By carving out time to experiment, test hypotheses, and implement platform advancements, you’re setting yourself up to leapfrog ahead. In the world of DataOps, standing still is essentially moving backwards.
This post has covered a lot of ground. DataOps is all about the art of applying the best practices from physical manufacturing and software engineering and applying it to the data software domain. It is about using first principles to address the distinct challenges inherent in working with data.
Data comes from a different world. It is the realm of statisticians and bookkeepers. The rigour that was instilled in software engineering is only now coming to data engineering. DataOps isn’t merely about adopting new tools or platforms, it’s a fundamental shift in approaching data work. It involves breaking down silos, embracing automated testing, and cultivating a culture of continuous improvement.
Picture our hypothetical intern again. A true DataOps environment should empower them to rename that production column within a day. Does this seem implausible in your current setup? If so, you have room to grow.
Databricks gives you a head start on this journey. It’s only your team’s specific application of the features Databricks offers (such as Unity Catalog and Delta Lake) that determines how robust your DataOps practice can become. Let’s frame this in The Three Ways:
- The First Way: Databricks as a whole streamlines your processes, reducing handoffs and improving the flow of work from Dev to Ops. The Lakehouse architecture and Unity Catalog simplify your data infrastructure and eliminate toil.
- The Second Way: With Delta Lake and Unity Catalog, you can enable safe and reliable feedback loops for your developers.
- The Third Way: Databricks constantly innovates on behalf of its customers (like the 73% speed improvement in DBSQL queries over two years). To capture these benefits, it is imperative to have a culture of continuous experimentation and improvement. This helps you stay aligned with the Databricks roadmap while combating the gradual degradation that comes with accumulating tech debt.
Your path to DataOps on Databricks is unique. It requires commitment, experimentation, and a willingness to challenge the status quo. Focus on how Databricks can help you streamline the machinery that produces analytics so that your engineers can spend time doing the things that matter.
The payoff is substantial: faster insights delivery, more reliable data products, and a more agile, responsive data team.
I encourage you to apply what you’ve learned here. Start small if needed, explore how Unity Catalog can streamline your data governance, or perhaps implement a simple testing framework. Take that first step toward DataOps.
In the next chapter, we will explore how Databricks can dramatically improve the flow of work from Dev to Ops. Databricks Asset Bundles are an obvious candidate here, but the answer might surprise you. Hint: It involves leveraging one of the best properties of a data lake.